| Тренинги и семинары | Проекты | Статьи | Фотографии | Услуги | Контакты | IEEE | О центре |
ДИСПЕРСИОННЫЙ АНАЛИЗОбщие положения Дисперсионный анализ предназначен для сравнения нескольких средних значений или для выявления степени влияния различных факторов на выходные параметры. Иначе говоря, это анализ изменчивости признака под влиянием каких-либо контролируемых переменных факторов. Заключения относительно математических ожиданий, оценками которых по экспериментальным данным являются средние арифметические значения параметров, делаются с помощью сравнения выборочных дисперсий, вычисленных двумя различными методами. Задача дисперсионного анализа состоит в том, чтобы из общей вариативности признака вычленить: Если имеем дело с многофакторным процессом, то с помощью дисперсионного анализа удается определить дисперсии, обусловленные действием каждого фактора в отдельности, и оценить статистическую значимость этих величин. Используемые в дисперсионном анализе критерии значимости основаны на предположении о том, что распределение вероятностей является нормальным или же другим стандартным распределением, связанным с нормальным (?2, t-распределение, F ? Фишера). Однофакторный дисперсионный анализ в системе Statistica Рассмотрим пример проверки гипотезы на уровне значимости 0,05 о том, что водонасыщение образцов грунта, взятого с разных экспериментальных полигонов (табл.), различно. С каждого полигона было взято по 10 образцов. Задача состоит в проверке гипотезы H0 о равенстве математических ожиданий случайных величин ?водонасыщения образцов грунта, взятого с трёх экспериментальных полигонов. Таблица
Создадим таблицу с двумя столбцами 30 строками. В Var 1 занесём данные по водонасыщению образцов из табл. 9.2, в Var 2 – обозначения групп, определяющих номер полигона – 1 (первые 10 строк), 2 (строки 11–20), 3 (строки 21–30). Схема дисперсионного анализа применима и в тех случаях, когда градации фактора отличаются лишь качественно, например, цвет окраски, музыкальный жанр; разные формы заболевания, разные экспериментаторы и т.д. Расчёты выполняются в модуле Statistics/ Basic Statistics and Tables/ Breakdown and one-way ANOVA (однофакторный дисперсионный анализ).
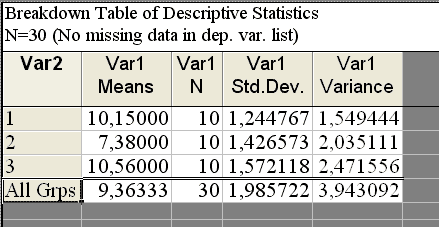
В окне результатов (рис. 9.2) во вкладке Descriptives отметим следующие статистики: Valid N (количество наблюдений), Standard deviations (стандартные отклонения) и Variances (дисперсии).
Нажав кнопку Summary, получим таблицу результатов (рис. 9.3).
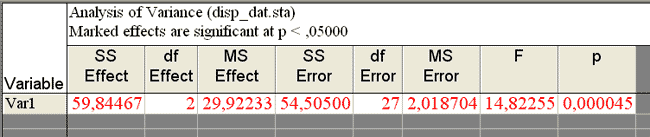
Возвратимся в предыдущее окно. Перейдя к вкладке ANOVA & tests, выполним дисперсионный анализ, нажав кнопку Analysis of Variance (дисперсионный анализ). В таблице дисперсионного анализа приводятся: Метод дисперсионного анализа позволяет определить, что перевешивает ? вариативность признака внутри групп или между группами
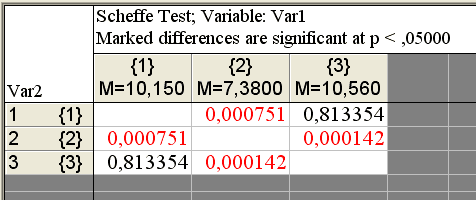
Так как вычисленный уровень значимости р меньше заданного уровня значимости 0,05, то гипотеза о равенстве средних отвергается. Таким образом, водонасыщение образцов грунта, взятых с разных полигонов, различно.
Проверка предположений дисперсионного анализа Напомним, что при применении дисперсионного анализа предполагается, что исходные данные – независимые выборки наблюдений, полученные из нормально распределённых генеральных совокупностей, имеющих одну и ту же дисперсию. выполнение этих предположений можно проверить в пакете Statistica. Один из способов проверки нормальности состоит в том, что исходные данные по группам наносятся на нормальный вероятностный график. Для этого в окне результатов во вкладке ANOVA & tests нужно нажать кнопку Categorized normal prob. plots (категоризованные нормальные вероятностные графики). Для наших данных получим следующие графики.
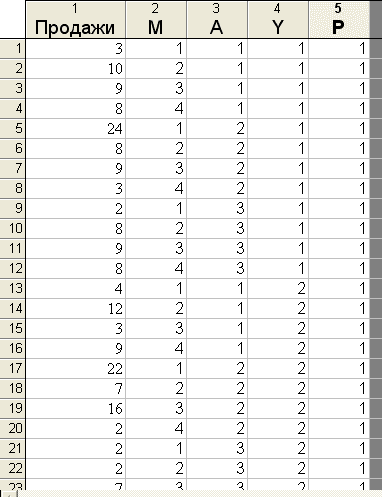
Точки, соответствующие нормально распределённым данным, укладываются на прямые. Как показывают графики, исходные данные достаточно плотно группируются относительно прямых. Многофакторный дисперсионный анализ Многофакторный дисперсионный анализ рассмотрим на следующем примере. Четыре группы продавцов продавали штучный товар. Каждая группа была подготовлена по определённой методике (фактор M=1, 2, 3, 4). Товар рекламировался по телевидению, в газете и по радио (фактор A=1, 2, 3). Кроме того, он был расфасован в различные упаковки (фактор Y=1, 2, 3). Эксперимент повторялся дважды (P=1, 2). После окончания двух сроков были получены следующие результаты по количеству продаж Таблица
Фрагмент таблицы с исходными данными приведен на рис. 9.7.
Для расчётов необходимо выполнить команду Statistics/ ANOVA/ Main effects ANOVA. По нажатию кнопки Variables определите переменные: Dependent variable list – Продажи, Categorical predictors (factors) – все остальные, и нажмите ОК. Теперь достаточно нажать кнопку All effects, и на экране появятся результаты общего дисперсионного анализа. Если эти результаты выделены красным цветом, – фактор оказывает существенное влияние. Более строго, анализируя критерий Фишера или значение р, можно сказать, что на количество продаж существенное влияние оказывают факторы M (методика обучения) и A (реклама). Результаты Примеры, рассмотренные в этой главе, демонстрируют технику вычислений в системе Statistica. Применение дисперсионного анализа, как и большинства других статистических методов для получения обоснованных и практически важных выводов требует значительно больше исходных данных. Только в этом случае можно говорить о проверке нормальности и других предположений. Вопрос о том, насколько оправдано применение параметрических статистических методов, является достаточно сложным. В связи с этим, в тех случаях, когда выполнение предположений дисперсионного анализа проблематично, следует использовать также и соответствующие непараметрические процедуры и сравнить результаты. Вообще F-критерий очень устойчив к отклонению от нормальности. Если эксцесс больше нуля, то значение F-статистики может стать очень маленьким. Нулевая гипотеза при этом не может быть отвергнута, хотя она и не верна. Ситуация меняется на противоположную, если эксцесс меньше нуля. Асимметрия распределения обычно незначительно влияет на F-статистику. Если число наблюдений в ячейке достаточно большое, то отклонение от нормальности не имеет особого значения в силу центральной предельной теоремы, в соответствии с которой распределение среднего значения при большом объёме выборки близко к нормальному независимо от начального распределения. |
Система статистических методов управления –
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Дисперсионный анализ особенно эффективен на производстве из-за неограниченной возможности повторить опыт нужное количество раз |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Понятие ?фактор? ещё используется в факторном анализе, где в отличие от дисперсионного анализа обозначает обобщенную переменную |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Дисперсионный анализ позволяет констатировать изменение признака, но при этом не указывает направление этих изменений |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Дисперсионный анализ относится к группе параметрических методов, и поэтому его следует применять только когда известно или доказано, что распределение признака является нормальным |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Схема дисперсионного анализа применима и в тех случаях, когда градации фактора отличаются лишь качественно, например, цвет окраски, музыкальный жанр; разные формы заболевания, разные экспериментаторы и т.д. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Метод дисперсионного анализа позволяет определить, что перевешивает – вариативность признака внутри групп или между группами |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Статистика – самая точная из всех неточных наук |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Система статистических методов управления – |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Желаете участвовать в семинаре? Хотите написать? Электронная почта - tomsk@ieee.org (Стукач Олег Владимирович) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||