| Тренинги и семинары | Проекты | Статьи | Фотографии | Услуги | Контакты | IEEE | О центре |
Первичная обработка данных и вычисление элементарных статистикВероятность и достоверность Большинство из нас специально не изучало теории вероятностей и математической статистики и либо слабо разбирается, либо вовсе не знакомо с ней. Ближе всего мы подходим к статистике, изучая приближённые вычисления. К сожалению, на этом знакомство со случайностью в школе обычно и заканчивается. Учителя явно боятся знакомить детей с вопросами, на которые нельзя дать точный ответ. В современной жизни вряд ли найдется область, где нельзя было бы с пользой применить, пусть в самой простой форме, научной статистики. Кем бы вы ни были, если в процессе работы вам приходится истолковывать фактический материал, вы можете обойтись без статистики, но её незнание отрицательно скажется на результатах вашей работы. Многие ошибочно считают, что уяснение теории вероятностей им не под силу. Для того чтобы рассеять это заблуждение, следует напомнить, что существуют разные степени знакомства с теорией вероятностей, каждой из которых достаточно, чтобы с пользой применять эту теорию в работе. Можно научиться «мыслить категориями теории вероятностей», уяснив смысл примерно двух десятков терминов, например, таких, как вероятность, кривая нормального распределения, среднее значение, медиана, мода, среднее квадратичное отклонение, средняя квадратичная ошибка, случайная ошибка, дисперсия, корреляция, статистическая значимость. Особенно важно понять характер различия между средними величинами, а также такие термины, как квартиль, ошибки выборочного метода, доверительные интервалы и т. д. Таким путём можно получить представление о теории вероятностей и здраво судить о соответствующих понятиях. Хотя производить необходимые вычисления так научиться нельзя. Это более серьёзная степень владения предметом теории вероятностей. Третья, высшая степень – изучить или вновь освоить методы математического анализа, логику и математическую статистику так, чтобы стать специалистом в этой области и получить возможность справиться со многими трудностями, связанными с применением теории вероятностей в работе. «Мышление категориями теории вероятностей» и восприятие мира через призму статистики помогает вырабатывать правильное представление о явлениях, которые мы изучаем, и является ценным методом решения многих задач. Генеральная совокупность и выборка Множество всех обследуемых объектов называется генеральной совокупностью. Если это множество содержит небольшое число элементов, то возможно полное обследование всех его элементов. Однако в большинстве случаев в силу того, что генеральная совокупность имеет очень много элементов либо её элементы труднодоступны, либо по другим причинам обследуется некоторая часть генеральной совокупности – выборка. В этом случае основные характеристики генеральной совокупности оцениваются (то есть определяются приближенно) по выборке. Соответствующие статистики называются «выборочное среднее», «выборочная дисперсия» и т. д. Очевидно, что не всякая выборка правильно отражает свойства генеральной совокупности. Например, нельзя судить о среднем душевом доходе населения по выборке, составленной из доходов служащих финансовых компаний. Выборка должна давать правильное, неискажённое представление о генеральной совокупности, или, как говорят, должна быть репрезентативной. Для такой выборки представление о параметрах технологических процессов будет отражать реальное положение, если пропорции между вероятностями появления показателя качества продукции в выборке соответствуют пропорциям в генеральной совокупности. Если свойства генеральной совокупности заранее неизвестны, то за неимением лучшего следует использовать простой случайный выбор. Это означает, что все элементы генеральной совокупности должны иметь равные шансы попасть в выборку. Простейшие описательные статистики Так как значения переменных не постоянны, нужно описывать их изменчивость. Для этого придуманы описательные или дескриптивные статистики: минимум, максимум, среднее, дисперсия, стандартное отклонение, медиана, квартили, мода и так далее. Идея этих статистик очень проста: вместо того чтобы рассматривать все значения переменной, а их может быть очень много, вначале стоит просмотреть описательные статистики. Они дают общее представление о значениях, которые принимает переменная. Расчёт описательных статистик производится при помощи модуля Statistics/ BasicStatistics/ Tables. В этом модуле объединены наиболее часто использующиеся на начальном этапе обработки данных процедуры. При вызове модуля Descriptivestatistics (Описательные статистики) появляется диалоговое окно, в котором при помощи кнопки Variables следует выбрать переменные для анализа. Для построения гистограмм и таблиц частот используются кнопки Frequencytables и Histograms соответственно. Чтобы выбрать статистики, подлежащие вычислению, нужно воспользоваться вкладкой Advancedэтого диалогового окна. Возможен расчёт следующих описательных статистик. Valid N – объем выборки. Mean – среднее арифметическое. Это наиболее часто используемое среднее, поскольку в расчет здесь принимаются все без исключения значения. Часто называемое просто средним, среднее арифметическое определяется как сумма наблюдений, делённая на их количество. Среднее значение случайной величины представляет собой наиболее типичное, наиболее вероятное её значение, своеобразный «центр», вокруг которого разбросаны все значения признака. Точно так же, как люди могут иметь различные мнения по поводу местонахождения центра города, есть и различные способы оценки среднего значения набора данных. Примерами различных типов средних значений служат среднее арифметическое, полусумма крайних значений, медиана, мода, геометрическое среднее и гармоническое среднее. Все типы средних имеют одно простое общее свойство. Среднее всегда не меньше минимального наблюдаемого значения и не больше максимального наблюдаемого значения. Отсюда следует, что если все наблюдения имеют одно и то же значение, то и все различные типы средних также должны равняться этому значению. Полусумма крайних значений определяется как полусумма минимального и максимального наблюдаемых значений. Median – медиана. Медианой является такое значение случайной величины, которое разделяет все наблюдения выборки на две равные по численности части. Медиана – это величина, находящаяся посередине набора данных, когда в нём все наблюдения упорядочены по возрастанию; если число наблюдений чётно, то имеются два «срединных» значения, и медиана равна их полусумме. Мода представляет собой наиболее часто встречающееся значение, и поэтому в некоторых наборах данных могут быть две или более моды, имеющие одну и ту же частоту. Sum – сумма. StandardDeviation – стандартное отклонение. Стандартное отклонение (или среднее квадратическое отклонение) является мерой изменчивости (вариации) признака. Оно показывает, на какую величину в среднем отклоняются наблюдения от среднего значения признака. Особенно большое значение стандартное отклонение имеет при исследовании нормальных распределений. В нормальном распределении 68% всех наблюдений лежит в интервале плюс-минус одного отклонения от среднего, 95% – плюс-минус двух стандартных отклонений от среднего и 99,7% всех наблюдений – в интервале плюс-минус трех стандартных отклонений от среднего. Variance – дисперсия. Дисперсия является мерой изменчивости, вариации признака и представляет собой средний квадрат отклонений наблюдений от среднего значения признака. В отличие от других показателей вариации дисперсия может быть разложена на составные части, что позволяет тем самым оценить влияние различных факторов на вариацию признака. Дисперсия – один из существеннейших показателей, характеризующих явление или процесс, один из основных критериев возможности создания достаточно точных моделей. Standard error of mean – стандартная ошибка среднего. Стандартная ошибка среднего – это величина, на которую отличается среднее значение выборки от среднего значения генеральной совокупности при условии, что распределение близко к нормальному. 95% confidence limits of mean – 95%-ый доверительный интервал для статистического анализа. Это интервал, в который с вероятностью 0,95 попадает среднее значение признака генеральной совокупности. Интервал выбирается при помощи вкладки Categ. plots (рис. 3.2). Наиболее часто используется вероятность 0,95 (95%). Вероятности 0,95 соответствует уровень значимости 0,05 (5%), установленный по умолчанию. Minimum, maximum – минимальное и максимальное значения. Lower, upper quartiles – нижний и верхний квартили. Квартилями называются такие величины Q1 и Q3, что одна четвертая часть наблюдений меньше или равна Q1 и три четверти наблюдений меньше или равны Q3. Ясно, что мы можем подобным образом определить и величину Q2, которая в этом случае является медианой. Часто величину Q1 называют нижней квартилью, а величину Q3 – верхней. Разность между ними называется интерквартильной широтой. Quartile range – интерквартильная широта. Range – размах. Skewness – асимметрия. Асимметрия характеризует степень смещения вариационного ряда относительно среднего значения по величине и направлению. В симметричной кривой коэффициент асимметрии равен нулю. Если правая ветвь кривой, начиная от вершины) больше левой (правосторонняя асимметрия), то коэффициент асимметрии больше нуля. Если левая ветвь кривой больше правой (левосторонняя асимметрия), то коэффициент асимметрии меньше нуля. Асимметрия менее 0,5 считается малой. Standard error of Skewness – стандартная ошибка асимметрии. Kurtosis – эксцесс. Эксцесс характеризует степень концентрации случаев вокруг среднего значения и является своеобразной мерой крутости кривой. В кривой нормального распределения эксцесс равен нулю. Если эксцесс больше нуля, то кривая распределения характеризуется островершинностью, т.е. является более крутой по сравнению с нормальной, а случаи более густо группируются вокруг среднего. При отрицательном эксцессе кривая является более плосковершинной, то есть более пологой по сравнению с нормальным распределением. Standard error of Kurtosis – стандартная ошибка эксцесса. Примеры вычисления описательных статистик Приведём пример вычисления описательных статистик для любимой около-экономическими кругами задачи – «расчёта среднего дохода» на предприятии, в регионе, в стране. Для эксперимента возьмём следующую выборку. Мы будем условно считать, что вышли на улицу и спросили первых 12 попавшихся нам человек о размере их дохода (в условных денежных единицах) предполагая, что 12 наблюдений – это репрезентативная выборка и её вполне достаточно для формулировки выводов.
Рассчитаем среднее арифметическое, являющееся в данном случае оценкой математического ожидания, медиану, моду и квартили.
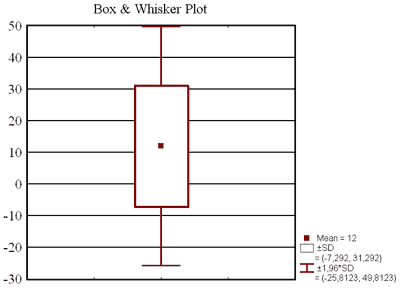
Итак, «средний доход» ничего не говорит о реальном положении дел. Он составил по расчёту 12 условных денежных единиц, в то время как нищее большинство – четверть всей выборки имеет доход ниже 3,0 (нижняя квартиль), а три четверти – ниже 8,0. Такая характеристика, как медиана гораздо лучше описывает нашу выборку, свидетельствуя, что половина населения в выборке имеет доход ниже 4,0. Это опять таки меньше «среднего дохода». Но если уж вычислять среднее, то хотя бы среднее геометрическое, а не арифметическое. Визуализация описательных статистик Для визуализации описательных статистик можно построить «графики коробок» («ящики с усами»). С помощью этого графика можно быстро оценить данные на предмет структуры распределения, наличия неправдоподобных измерений, однородности наблюдений и так далее. Это легко можно сделать при помощи кнопки Box & Whiskerplotforallvariables окна Descriptivestatistics.
Как видно, в этом случае построение графика для среднего значения не очень показательно. Правильнее сказать, из него ничего не видно. По рис. можно определить, что выборка крайне неоднородна. Наличие длинного верхнего уса говорит о том, что людей с высоким доходом, вытягивающих статистику «среднего дохода» вверх, очень немного. Основная масса нищеты – это 75 процентов населения (три квартиля снизу до 8 денежных единиц). Половина выборки имеет доход от 3 до 8 денежных единиц, что опять таки ниже «среднего дохода». Тот, кто знаком с теорией вероятностей, понимает, что медиана или мода лучше выражают срединную тенденцию повторяемости большого количества величин, чем среднее арифметическое значение.
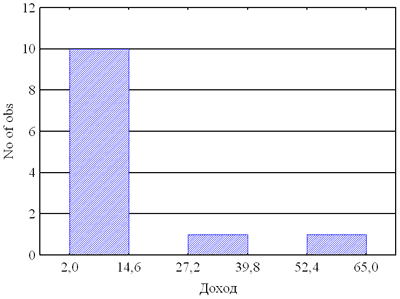
В модуле описательных статистик можно представить распределение переменных на гистограммах. Для этого предназначена кнопка Histograms. Для нашего примера с доходом гистограмма подтверждает выводы, сделанные из графиков коробок о неправомерности оценки выборки только по одному среднему арифметическому значению.
На гистограмму при необходимости можно наложить плотность нормального распределения, проверить близость распределения к нормальному виду при помощи критериев Колмогорова-Смирнова, Лилиефорса; вычислить статистику Шапиро-Уилкса. Для этого в группе опций Distribution необходимо установить флажок напротив соответствующих статистик. Значения статистик показываются прямо на гистограммах. Нормальное распределение Нормальное распределение играет важную роль в статистике по многим причинам. Распределение большого числа статистик является нормальным или может быть получено из нормального с помощью некоторых преобразований. Нормальное распределение дает хорошую модель для реальных явлений, в которых:
Множество величин на практике имеют нормальное распределение, например, распределение приращений индексов развитых стран, курсы акций, распределение погрешностей измерения, отклонение большинства параметров продукции от номинальных величин при её изготовлении и т.д. Характерное свойство нормального распределения состоит в том, что 68,27 % из всех его наблюдений лежат в диапазоне одного стандартного отклонения от среднего [µ–σ, µ+σ], диапазон два стандартных отклонения [µ–2σ, µ+2σ] включает 95,45 % значений, диапазон три стандартных отклонения [µ–3σ, µ+3σ] включает 99,73 % значений. Таким образом, за пределами ±3σ относительно µ вероятность появления случайной величины не превышает значения 0,27 %. Это знаменитое правило «три сигма», чрезвычайно популярное на практике. Обычно отдельные величины группируются вокруг определённого среднего значения и по мере удаления от него дисперсия всё более и более увеличивается. Величины, наиболее удалённые от среднего значения, могут существенным образом отличаться от основной массы величин данной группы. В каждом конкретном случае нужно чётко знать, что представляет интерес: основная масса величин или крайние для данной группы величины. Степень отклонения крайних величин от среднего зависит обычно от трёх факторов:
О нормальности распределения можно судить по графику, который называется «нормальный вероятностный график». Его легко построить при помощи опции Normalprobabilityplotsокна «Descriptivestatistics». Чем ближе распределение к нормальному виду, тем лучше значения ложатся на прямую линию. Этот метод оценки является фактически глазомерным. В сомнительных случаях проверку на нормальность можно продолжить с использованием специальных статистических критериев (Колмогорова-Смирнова, хи-квадрат). Однако детальная проверка гипотезы о нормальности выборки требует довольно значительных объемов выборки (не менее 100 наблюдений). Технологическое рассеяние и допуск на контролируемый показатель качества Причиной появления того или иного значения случайной величины является то, что она формируется под воздействием большого числа влияющих факторов. Промышленное производство как раз связано с тем, что на его контролируемые показатели влияет множество факторов, неизбежным следствием чего является распределение показателей по нормальному закону. Так, при производстве деталей для машин, приборов и оборудования материалы могут иметь некоторый разброс в свойствах, например, иметь разные физические характеристики по объему или от партии к партии. Станки и оборудование каждый раз настраиваются с некоторыми вариациями, в процессе работы изнашиваются, а резцы тупятся. Процесс измерения параметра сопровождается погрешностями измерения, присущими как средствам и методам измерения, так и операторам. Внешние условия, в которых протекает процесс, могут испытывать колебания, например, изменяется температура, влажность, давление. В приёмах выполнения различных операций проявляются индивидуальные подходы операторов и т.д. Все эти факторы оказывают влияние на контролируемые показатели качества продукции, которые будут распределены в соответствии с нормальным законом со средним µ и стандартным отклонением σ. Одной из основных характеристик технологического процесса наряду с µ и σ является поле рассеяния, или полное технологическое рассеяние. Этообласть значений контролируемого показателя, в которой он появляется с вероятностью, близкой к единице. Для нормального закона такой областью считают интервал [µ–3σ, µ+3σ], в котором вероятность появления контролируемого показателя равна 0,9973. То есть поле рассеяния – это интервал, равный 6σ. |
|
||||||||
«Сомнительно, чтобы где-нибудь, помимо банка, где клерки пересчитывают грязными руками чужие медяки, точность, на которую способна арифметика, имела какую-либо ценность» |
|||||||||
Извлечь пользу из большого количества цифр едва ли удастся, если не применить какой-либо обобщающий показатель |
|||||||||
Среднее арифметическое часто используется, но нечасто помогает понять явление |
|||||||||
Статистическое мышление включает в себя: |
|||||||||
У всех нас в голове имеется прибор, учитывающий вероятные явления |
|||||||||
Существуют две причины использования «среднего дохода» в газетно-телевизионной похвальбе чиновников друг перед другом: |
|||||||||
Профессора математики спрашивают: |
|||||||||
«Средний доход» – это «средняя температура по больнице». В среднем все здоровы |
|||||||||
Система статистических методов управления – |
|||||||||
| Желаете участвовать в семинаре? Хотите написать? Электронная почта - tomsk@ieee.org (Стукач Олег Владимирович) |